1.Jetson的环境配置
这个是具体的官网网站
目前的设备与文档略有不一样,为JetPack 5.1,所以在创建环境时,python为3.8.
conda
安装Archiconda而不是 Anaconda,因为后者不提供为 Jetson 构建的文件。
wget https://github.com/Archiconda/build-tools/releases/download/0.2.3/Archiconda3-0.2.3-Linux-aarch64.sh
bash Archiconda3-0.2.3-Linux-aarch64.sh -b
echo -e '\n# set environment variable for conda' >> ~/.bashrc
echo ". ~/archiconda3/etc/profile.d/conda.sh" >> ~/.bashrc
echo 'export PATH=$PATH:~/archiconda3/bin' >> ~/.bashrc
echo -e '\n# set environment variable for pip' >> ~/.bashrc
echo 'export OPENBLAS_CORETYPE=ARMV8' >> ~/.bashrc
source ~/.bashrc
conda --version安装完成后,创建conda环境并激活。
export PYTHON_VERSION=`python3 --version | cut -d' ' -f 2 | cut -d'.' -f1,2`
conda create -y -n mmdeploy python=${PYTHON_VERSION}
conda activate mmdeploy正如我上面所说对应JetPack不同版本对应不同python版本。
JetPack SDK 4+ 提供 Python 3.6。我们强烈建议使用默认 Python。尝试升级可能会破坏 JetPack 环境。
如果需要更高版本的Python,可以安装JetPack 5+,其中Python版本为3.8。查看JetPack版本
sudo apt-cache show nvidia-jetpackPyTorch
这里JetPack 对应的pytorch版本
这个是对应pytorch的网站PyTorch for Jetson
我安装的是torch 1.11,最低要求
这个是torch对应兼容的torchvision网站torch-torchvision

pytorch
wget https://nvidia.box.com/shared/static/ssf2v7pf5i245fk4i0q926hy4imzs2ph.whl -O torch-1.11.0-cp38-cp38-linux_aarch64.whl #名字都得对上,不然安装不上
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
# torchvision
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev libopenblas-base libopenmpi-dev libopenblas-dev -y
git clone --branch v0.12.0 https://github.com/pytorch/vision torchvision
cd torchvision
export BUILD_VERSION=0.12.1
pip install -e .在 Jetson Nano 上安装 torchvision 大约需要 30 分钟。请耐心等待安装完成。
CMake
CMake 版本
cmake --version# purge existing
sudo apt-get purge cmake -y
# install prebuilt binary
export CMAKE_VER=3.23.1
export ARCH=aarch64
wget https://github.com/Kitware/CMake/releases/download/v${CMAKE_VER}/cmake-${CMAKE_VER}-linux-${ARCH}.sh
chmod +x cmake-${CMAKE_VER}-linux-${ARCH}.sh
sudo ./cmake-${CMAKE_VER}-linux-${ARCH}.sh --prefix=/usr --skip-license
cmake --version安装依赖项
Jetson 平台上 MMDeploy 的模型转换器依赖于MMCV和推理引擎TensorRT。而 MMDeploy C/C++ 推理 SDK 则依赖于spdlog、OpenCV 和ppl.cv等,以及 TensorRT 。因此,在接下来的章节中,我们将介绍如何准备 TensorRT 。然后,我们将分别介绍如何安装模型转换器和 C/C++ 推理 SDK 的依赖项。
准备 TensorRT
TensorRT 已经打包到 JetPack SDK 中。但为了在 conda 环境中成功导入,我们需要将 tensorrt 包复制到之前创建的 conda 环境中。
cp -r /usr/lib/python${PYTHON_VERSION}/dist-packages/tensorrt* ~/archiconda3/envs/mmdeploy/lib/python${PYTHON_VERSION}/site-packages/
conda deactivate
conda activate mmdeploy
python -c "import tensorrt; print(tensorrt.__version__)" # Will print the version of TensorRT
# set environment variable for building mmdeploy later on
export TENSORRT_DIR=/usr/include/aarch64-linux-gnu
# append cuda path and libraries to PATH and LD_LIBRARY_PATH, which is also used for building mmdeploy later on.
# this is not needed if you use NVIDIA SDK Manager with "Jetson SDK Components" for installing JetPack.
# this is only needed if you install JetPack using SD Card Image Method.
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64您还可以通过将上述环境变量添加到来使其永久化~/.bashrc。
echo -e '\n# set environment variable for TensorRT' >> ~/.bashrc
echo 'export TENSORRT_DIR=/usr/include/aarch64-linux-gnu' >> ~/.bashrc
# this is not needed if you use NVIDIA SDK Manager with "Jetson SDK Components" for installing JetPack.
# this is only needed if you install JetPack using SD Card Image Method.
echo -e '\n# set environment variable for CUDA' >> ~/.bashrc
echo 'export PATH=$PATH:/usr/local/cuda/bin' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64' >> ~/.bashrc
source ~/.bashrc
conda activate mmdeploy安装模型转换器的依赖项
安装 MMCV
MMCV没有为 Jetson 平台提供预构建包,因此我们必须从源代码构建它。
sudo apt-get install -y libssl-dev
git clone --branch 2.x https://github.com/open-mmlab/mmcv.git
cd mmcv
MMCV_WITH_OPS=1 pip install -e .在 Jetson Nano 上安装 MMCV 大约需要 1 小时 40 分钟。请耐心等待安装完成。
安装 ONNX
不要安装最新的 ONNX。建议的 ONNX 版本是 1.10.0。
# Execute one of the following commands
pip install onnx==1.10.0
conda install -c conda-forge onnx如果安装失败并显示以下错误:
CMake Error at CMakeLists.txt:299 (message):
Protobuf compiler not found请安装依赖项:
sudo apt-get install protobuf-compiler libprotoc-dev安装 ONNX 运行时 [可选]
前往Jetson_Zoo#ONNX_Runtime找到正确版本的 onnx 运行时。然后下载并安装软件包。
我按照对应的版本安装的是onnxruntime 1.15.1
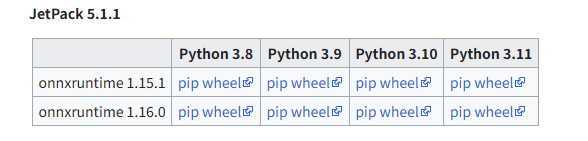
# Download pip wheel from location mentioned above
$ wget https://nvidia.box.com/shared/static/mvdcltm9ewdy2d5nurkiqorofz1s53ww.whl -O onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl
# Install pip wheel
$ pip3 install onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl安装h5py和pycuda
模型转换器采用HDF5保存TensorRT INT8量化的校准数据,需要pycuda复制设备内存。
sudo apt-get install -y pkg-config libhdf5-100 libhdf5-dev
pip install versioned-hdf5 pycudaversioned-hdf5可能因为版本而安装不上,可以使用conda进行安装,pycuda正常安装。
conda install -c conda-forge h5py=2.10.0 hdf5在 Jetson Nano 上安装 versioned-hdf5 大约需要 6 分钟。请耐心等待安装完成。
安装 C/C++ 推理 SDK 的依赖项
安装 spdlog
spdlog是一个非常快的、仅有头文件/编译的 C++ 日志库
sudo apt-get install -y libspdlog-dev安装 ppl.cv
ppl.cv是openPPL的一个高性能图像处理库
git clone https://github.com/openppl-public/ppl.cv.git
cd ppl.cv
export PPLCV_DIR=$(pwd)
echo -e '\n# set environment variable for ppl.cv' >> ~/.bashrc
echo "export PPLCV_DIR=$(pwd)" >> ~/.bashrc
./build.sh cuda在 Jetson Nano 上安装 ppl.cv 大约需要 15 分钟。请耐心等待安装完成。
安装 MMDeploy
git clone -b main --recursive https://github.com/open-mmlab/mmdeploy.git
cd mmdeploy
export MMDEPLOY_DIR=$(pwd)安装模型转换器
由于 OpenMMLab 代码库采用的一些运算符不受 TensorRT 支持,我们构建了自定义 TensorRT 插件来弥补,例如roi_align、等。您可以从这里scatternd找到自定义插件的完整列表。
# build TensorRT custom operators
mkdir -p build && cd build
cmake .. -DMMDEPLOY_TARGET_BACKENDS="trt"
make -j$(nproc) && make install
# install model converter
cd ${MMDEPLOY_DIR}
pip install -v -e .
# "-v" means verbose, or more output
# "-e" means installing a project in editable mode,
# thus any local modifications made to the code will take effect without re-installation.在 Jetson Nano 上安装模型转换器大约需要 5 分钟。请耐心等待安装完成。
安装 C/C++ 推理 SDK
构建 SDK 库及其演示如下:
mkdir -p build && cd build
cmake .. \
-DMMDEPLOY_BUILD_SDK=ON \
-DMMDEPLOY_BUILD_SDK_PYTHON_API=ON \
-DMMDEPLOY_BUILD_EXAMPLES=ON \
-DMMDEPLOY_TARGET_DEVICES="cuda;cpu" \
-DMMDEPLOY_TARGET_BACKENDS="trt" \
-DMMDEPLOY_CODEBASES=all \
-Dpplcv_DIR=${PPLCV_DIR}/cuda-build/install/lib/cmake/ppl
make -j$(nproc) && make install在 Jetson Nano 上构建 SDK 库大约需要 9 分钟。请耐心等待安装完成。
运行演示
物体检测演示
在运行此演示之前,您需要转换模型文件才能与此 SDK 一起使用。
1.安装模型转换所需的MMDetection
MMDetection 是一个基于 PyTorch 的开源对象检测工具箱
git clone -b 3.x https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e . # or "python setup.py develop"2.按照本文档了解如何转换模型文件。
在本例中,我们使用retinanet_r18_fpn_1x_coco.py作为模型配置,并使用该文件作为相应的检查点文件。此外,对于部署配置,我们使用了detection_tensorrt_dynamic-320x320-1344x1344.py 。
python ./tools/deploy.py \
configs/mmdet/detection/detection_tensorrt_dynamic-320x320-1344x1344.py \
$PATH_TO_MMDET/configs/retinanet/retinanet_r18_fpn_1x_coco.py \
retinanet_r18_fpn_1x_coco_20220407_171055-614fd399.pth \
$PATH_TO_MMDET/demo/demo.jpg \
--work-dir work_dir \
--show \
--device cuda:0 \
--dump-info最后对图像进行推理

./object_detection cuda ${directory/to/the/converted/models} ${path/to/an/image}
下面是MMsegmentation的部署过程,以我自己的现有代码,复制到Jetson Nano中,然后安装环境,我现有的环境都安装在mmdeploy中。

cd mmsegmentation
pip install -v -e .在 Jetson 平台进行转换及部署
1.ONNX 模型转换
在 Jetson 平台下进入安装好的虚拟环境,以及mmdeploy 目录,进行模型ONNX转换。
python tools/deploy.py \
configs/mmseg/segmentation_onnxruntime_static-512x512.py \
../atl_config.py \
../deeplabv3plus_r18-d8_512x512_80k_potsdam_20211219_020601-75fd5bc3.pth \
../2_13_3584_2560_4096_3072.png \
--work-dir ../atl_models \
--device cpu \
--show \
--dump-info
转换成功后,您将会看到如下信息以及包含 ONNX 模型的文件夹:
10/09 19:58:22 - mmengine - INFO - visualize pytorch model success.
10/09 19:58:22 - mmengine - INFO - All process success.
2.TensorRT 模型转换
更换部署trt配置文件,进行 TensorRT 模型转换。
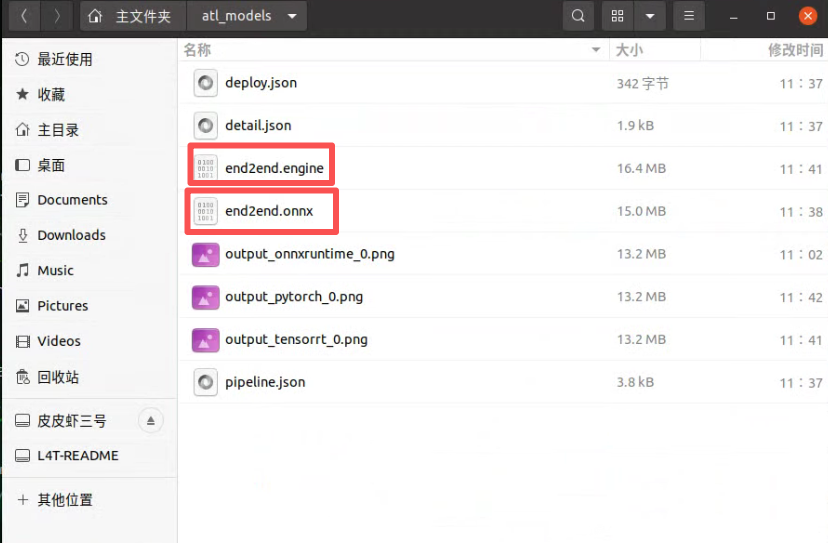
python tools/deploy.py \
configs/mmseg/segmentation_tensorrt_static-512x512.py \
../atl_config.py \
../deeplabv3plus_r18-d8_512x512_80k_potsdam_20211219_020601-75fd5bc3.pth \
../2_13_3584_2560_4096_3072.png \
--work-dir ../atl_trt_models \
--device cuda:0 \
--show \
--dump-info
转换成功后您将看到以下信息及 TensorRT 模型文件夹:
10/09 20:15:50 - mmengine - INFO - visualize pytorch model success.
10/09 20:15:50 - mmengine - INFO - All process success.
图片同上。
插曲:如果想让分割的图片没有标签,只是分割图,需要对mmseg中的代码进行更改。
第 312 行
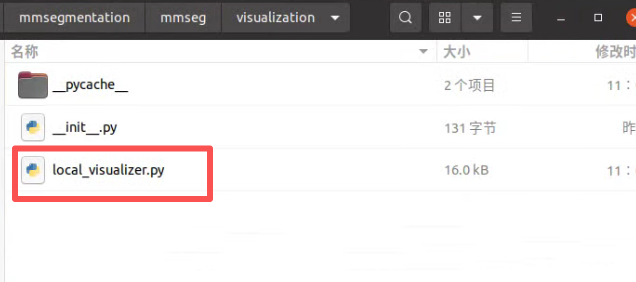
gt_img_data = self._draw_sem_seg(image, data_sample.gt_sem_seg,
classes, palette, with_labels=False)
第 329 行
pred_img_data = self._draw_sem_seg(image,
data_sample.pred_sem_seg,
classes, palette,
with_labels=False)
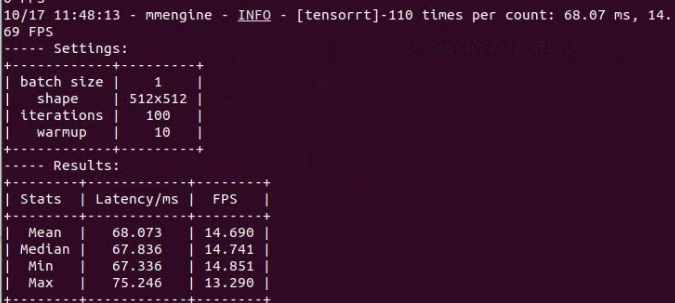
3.模型测速
执行以下命令完成模型测速,详细内容请查看 profiler
python tools/profiler.py \
${DEPLOY_CFG} \
${MODEL_CFG} \
${IMAGE_DIR} \
--model ${MODEL} \
--device ${DEVICE} \
--shape ${SHAPE} \
--num-iter ${NUM_ITER} \
--warmup ${WARMUP} \
--cfg-options ${CFG_OPTIONS} \
--batch-size ${BATCH_SIZE} \
--img-ext ${IMG_EXT}示例:
python tools/profiler.py \
configs/mmseg/segmentation_tensorrt_static-512x512.py \
../atl_config.py \
../atl_demo_img \
--model /home/sirs/AI-Tianlong/OpenMMLab/atl_trt_models/end2end.engine \
--device cuda:0 \
--shape 512x512 \
--num-iter 100测速结果:
4.模型推理
根据2中生成的TensorRT模型文件夹,进行模型推理。
from mmdeploy.apis.utils import build_task_processor
from mmdeploy.utils import get_input_shape, load_config
import torch
deploy_cfg='./mmdeploy/configs/mmseg/segmentation_tensorrt_static-512x512.py'
model_cfg='./atl_config.py'
device='cuda:0'
backend_model = ['./atl_trt_models/end2end.engine']
image = './atl_demo_img/2_13_2048_1024_2560_1536.png'
# read deploy_cfg and model_cfg
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
# build task and backend model
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
model = task_processor.build_backend_model(backend_model)
# process input image
input_shape = get_input_shape(deploy_cfg)
model_inputs, _ = task_processor.create_input(image, input_shape)
# do model inference
with torch.no_grad():
result = model.test_step(model_inputs)
# visualize results
task_processor.visualize(
image=image,
model=model,
result=result[0],
window_name='visualize',
output_file='./output_segmentation.png')即可得到推理结果:

蒸馏模型:
使用mmrazor进行教师学生蒸馏
蒸馏:
python tools/train.py /home/lsl/Workspace/mmrazor/configs/distill/mmseg/cwd/cwd_logits_segformer_B5_segformer_B0_-40k_voc-512x512.py
划分成学生权重:
python tools/model_converters/convert_kd_ckpt_to_student.py /home/lsl/Workspace/mmrazor/work_dirs/cwd_logits_segformer_B5_segformer_B0_-40k_voc-512x512-tau=1-loss_weight=1.25/best_mIoU_iter_37000.pth --out-path /home/lsl/Workspace/mmrazor/work_dirs/cwd_logits_segformer_B5_segformer_B0_-40k_voc-512x512-tau=1-loss_weight=1.25
量化模型:
将划分完的权重放入开发板上进行量化推理:
量化代码(tensorRT_int8):
python3 tools/deploy.py
/home/jiang/mmdeploy/configs/mmseg/segmentation_tensorrt-int8_static-512x512.py
/media/jiang/皮皮虾三号/jetson/cwd/segformer_mit-b0_8xb2-160k_ade20k-512x512/segformer_mit-b0_8xb2-160k_ade20k-512x512.py
/media/jiang/皮皮虾三号/jetson/cwd/best_mIoU_iter_37000_student.pth /media/jiang/皮皮虾三号/jetson/cwd/test-org-img/6336.jpg
--work-dir work_dir1
--device cuda --quant --quant-image-dir /media/jiang/皮皮虾三号/jetson/cwd/VOCdevkit/VOC2012/JPEGImages
模型测速(FPS):
python tools/profiler.py configs/mmseg/segmentation_tensorrt-int8_static-512x512.py
/media/jiang/皮皮虾三号/jetson/cwd/segformer_mit-b0_8xb2-160k_ade20k-512x512/segformer_mit-b0_8xb2-160k_ade20k-512x512.py
/media/jiang/皮皮虾三号/jetson/cwd/test-org-img --model /home/jiang/mmdeploy/work_dir/tensorint8/end2end.engine
--device cuda:0 --shape 512x512 --num-iter 100 --warmup 10
量化后进行mIoU测试(拥有测试数据集):
建议新建一个 deploy_eval_512.py(完整的配置文件config),内容放在原 config 最后:
deploy_test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=(512, 512), keep_ratio=False),
dict(type='LoadAnnotations'),
dict(type='PackSegInputs'),
]
test_pipeline = deploy_test_pipeline
val_pipeline = deploy_test_pipeline
test_dataloader['dataset']['pipeline'] = deploy_test_pipeline
val_dataloader['dataset']['pipeline'] = deploy_test_pipeline
再用这个 config 跑:
python tools/test.py \
configs/mmseg/segmentation_tensorrt_static-512x512.py \
/path/to/deploy_eval_512.py \
--model work_dir/tensor/end2end.engine \
--device cuda:0 \
--work-dir work_dirs/eval_trt_fp32